Schemaless, Not Structureless: A True Columnar Index for Log Data

Published on
Table of Contents
Logs are the wild west of telemetry. Every service logs differently, every team adds its own fields, and enrichment pipelines bolt on more — pod names, regions, build versions — long after the code was written. Each log line arrives as a loose bag of facets — key-value attributes — and no two lines carry quite the same bag. For decades, storage engines have forced an uncomfortable choice on this data: keep it flexible and query it slowly, or make it fast and lose the flexibility.
We built a storage index that removes that tradeoff: a schemaless index that gives every facet — whether it appears on a billion log lines or just three — a true, typed, compressed column of its own, created automatically at ingest time. This post explains how it works, why it is fundamentally faster than JSON-blob and row-oriented designs, and why it can keep absorbing new fields without ever asking for a schema migration. The design applies to any telemetry — traces, events, user sessions — but logs are where schema chaos is most extreme, so logs are the lens we'll use.
The problem: logs have no fixed shape
Consider four log lines from a single application fleet:

Three things make this data hard to store well:
The key space is unbounded. Across a fleet of services, teams, and deploys, the set of distinct facets runs into the thousands — and nobody can enumerate it up front.
Each line is sparse. Any single log line carries only a handful of those thousands of keys. Most keys are absent from most lines.
The shape changes constantly. Tomorrow's deploy starts logging
checkout.retries; next week's addsfeature.flag.variant. New keys appear daily, without warning or coordination.
Any storage design that demands a fixed schema either drops facets it didn't anticipate or turns every new log field into an engineering ticket. Any design that simply accepts arbitrary shapes has, historically, paid for that flexibility at query time. That is the gap this index closes.
The usual answers, and what they cost
Three architectural patterns dominate how analytical systems store log facets today.
1. The JSON blob. Store each line's facets as one serialized JSON string in a single column. Ingest is trivial and nothing is ever dropped — but every query pays the full price. Asking "what is the average duration_ms for the payments service?" means reading every blob, parsing every blob, and extracting one field from each, even though the other 99% of each blob is irrelevant to the question. Compression suffers too: a blob interleaves strings, numbers, and key names from unrelated facets, denying the compressor the long runs of similar data it thrives on.
2. Row-oriented document storage. Store each log line as a document, retrieved whole. This is excellent for "show me this one log line" — and structurally wrong for analytics. Faceting on a single key across ten million lines means reading ten million whole documents. Such systems stay fast only by building inverted indexes on everything in advance, multiplying ingest cost and storage for facets that may never be queried.
3. The rigid columnar schema. Classic columnar storage — the foundation of every fast analytical database — delivers exactly the read pattern log analytics wants: scan only the columns the query touches. But it demands the schema up front. Every new log field is a schema migration; every undeclared field is either dropped or stuffed into… a JSON blob, returning us to pattern 1.
A note on hybrid "map" and "variant" types. Some columnar engines offer a special column type for semi-structured data. These help, but most store the key-value pairs together row-wise inside the column, or extract only a fixed set of popular keys into real columns — so access to an arbitrary key still degrades to scanning and parsing everything else. A design is only truly columnar if every key, however rare, gets a real column.
| Row/document store | Rigid columnar | Schemaless index | |
|---|---|---|---|---|
Accepts any shape | ✅ | ✅ | ❌ | ✅ |
Reads only what the query needs | ❌ | ❌ | ✅ | ✅ |
Columnar compression | ❌ | ❌ | ✅ | ✅ |
New key requires migration | No | No | Yes | No |
Values stored typed (no re-parsing) | ❌ | partly | ✅ | ✅ |
The fourth column is the subject of the rest of this post.
The schemaless index: every key becomes a real column
The core idea is simple to state: decompose log lines at ingest time, so that every distinct facet gets its own typed, sparse column — automatically. Flexibility is preserved at the boundary where data arrives; full columnar structure exists everywhere data is stored and read.
Four structures make this work:
A key dictionary. Every distinct key, together with its inferred value type, gets one entry in a compact dictionary — the index's table of contents. service (string), status (integer), cart_value (decimal): one entry each, regardless of how many log lines carry them.
A sparse column per key. Each key's values are stored contiguously, in arrival order — but only for the lines that actually have the key. A key present on 1% of lines produces a column 1% the size of a dense one. Absence costs nothing; there are no nulls to store, pad, or skip.
A presence map per key. A compact bitmap (or, for very rare keys, a short list of row IDs) records exactly which lines carry the key. This is the bridge between "log line #7" and "the 3rd value in this column" — answered with a couple of bit operations, no scanning.
Typed values. Types are inferred per key at ingest: numbers are stored as numbers, strings as strings, booleans as booleans. If the same key ever arrives with two different types — status logged as the integer 200 by one service and the string "success" by another — they simply become two columns, each internally consistent. No coercion, no data loss, no errors.

Figure 1 — the same four log lines, stored as interleaved blobs versus decomposed into sparse, typed, per-key columns.
Crucially, all of this happens with zero configuration. When a log line arrives carrying a key the system has never seen, the dictionary grows by one entry and a new sparse column begins — in the time it takes to ingest that one line:
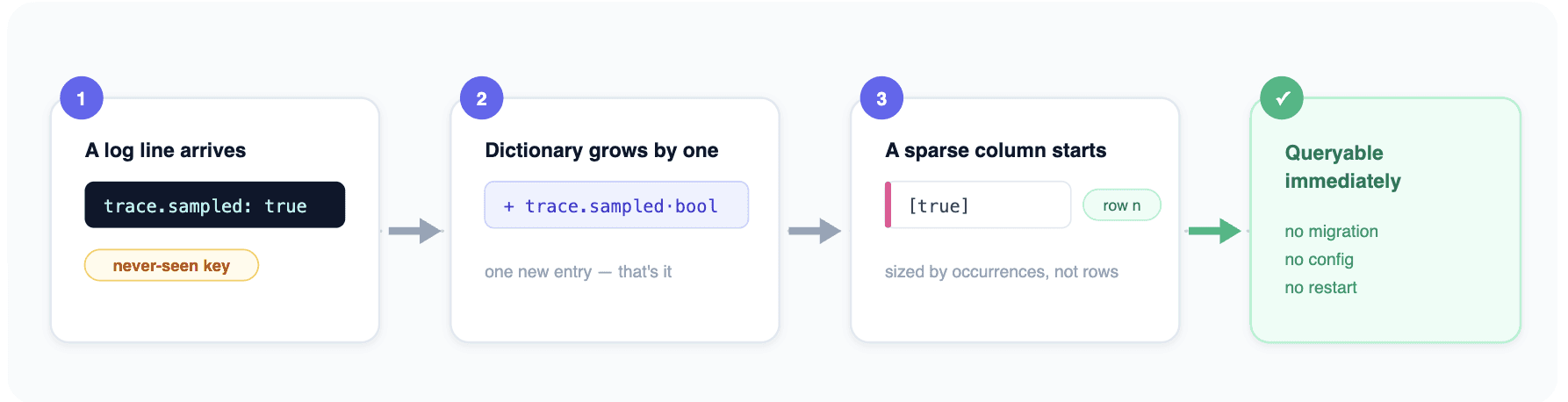
Figure 2 — a never-before-seen key becomes a queryable column as a side effect of ingesting one log line.
Why this is fast
Each speed advantage falls directly out of a structure above — no benchmarks required to see why.
I/O proportional to the question, not the data. A query touching one key out of 200 reads roughly 1/200th — about ~0.5% — of the facet data. The blob design reads and parses 100% of it to answer the same question. As teams add more facets, this gap widens: more keys make blobs slower and leave per-key columns untouched. This is what makes interactive log exploration — facet panels, group-bys, top-K breakdowns — feel instant instead of batch-like.
No parsing, ever. Values are stored already decoded and typed. Reading an integer is reading an integer — not tokenizing a JSON string, matching a key, and casting the result, multiplied by every log line in scope.
Compression that actually works. A column of 10,000 status codes is 10,000 small integers side by side — highly repetitive, exactly what block compressors are built for, and amenable to further per-column encodings. Ten thousand blobs interleave those integers with unrelated strings and key names, destroying the patterns. Columnar layout routinely compresses several times better on this kind of data, which also means proportionally fewer bytes to read at query time.
Encodings tailored to each key. Per-key columns unlock per-key encoding choices. Fixed-width values — integers, decimals, booleans — are stored in fixed-size slots, so the n-th value is located by pure arithmetic, with no scanning and no offsets to chase. Variable-width values like strings use an offset-indexed layout built for fast sequential scans. And a low-cardinality key — service with a few dozen distinct values across millions of lines — can go further with dictionary encoding: each distinct value stored once, with a small integer reference per line. That shrinks the column dramatically and lets filters and group-bys compare small integers instead of strings.
Sparsity is free. Rare keys cost almost nothing — a key on 1% of lines uses ~1% of the storage of a dense column, plus a tiny presence map. There is no penalty for letting teams log as many facets as they like, so there is no pressure to restrict them.

Figure 3 — one question, two read paths. The columnar path reads only the data the question is about.
Built to grow
Extensibility is not a feature added on top of this design — it is the design.
The data model evolves itself. New keys become columns automatically; new value types for an existing key coexist as sibling columns. The questions a rigid schema turns into migration projects — "can we add this field?", "can we change its type?" — simply do not arise.
Storage decisions are made per key. Compression codec and presence-map strategy are chosen per column, so a dense, hot key like service and a rare, cold one like checkout.retries each get the treatment that suits them.
The key is the unit of optimization. Because every facet already lives in its own column, future accelerations attach naturally at the same granularity — a heavily-filtered key can gain its own auxiliary index or sketch without touching any other key's data. The same unit the data is organized around is the unit the system optimizes around.
Conclusion
The flexibility-versus-performance tradeoff for log data was never a law of nature. It was an artifact of one decision: treating a flexible log line as an opaque blob and deferring all structure to query time. Move the decomposition to ingest — a dictionary of keys, a sparse typed column per key, a presence map to tie them together — and schemaless data gets the same first-class columnar treatment as any declared schema, with none of the ceremony.
Schemaless describes the input, not the storage. The log lines arrive with no fixed shape; what's stored is pure structure.
